-
Installation
-
With Kamon Telemetry
-
How To Guides
-
Migrations
-
-
Core Concepts
-
Foundations
-
Advanced
-
-
Instrumentation
-
Supported Frameworks
-
Akka
-
Akka HTTP
-
Cassandra Driver
-
Caffeine
-
Elasticsearch
-
Executors
-
Futures
-
JDBC
-
Kafka
-
Logback
-
Play Framework
-
Spring Framework
-
System Metrics
-
-
-
Reporters
-
Kamon APM
-
Using Kamon APM
-
Overview
-
Services
-
Traces
-
Dashboards
-
Alerts
-
Hosts
-
Investigating Issues
-
Settings and Administration
-
-
Context #
A Context is a immutable set of key-value pairs that contain state specific to the execution of a particular request
in your application. Each request should have its own Context and all instrumentation and manual Context manipulation must
ensure that Contexts from different requests are never mixed together.
The most common use case for a Context is to store additional request information like a request ID, user ID, user
language or correlation IDs. If there are pieces of information that you would typically store in a ThreadLocal
or the MDC, those are good candidates to be moved to Kamon’s Context. Additionaly, Kamon uses the Context propagation
mechanisms to carry around the tracer’s current Span.
Most of the time Kamon’s instrumentation will take care of creating, propagating and manipulating a Context for each request.
Keys #
Context keys are used to create new Context instances and to retrieve items from the Context. All keys encode four pieces of information required for Context propagation to work:
- The key name. Key names must be unique and they will be used on configuration settings.
- The value type. The return value of
.get(...)calls is tied to the Key. - The default value. This is the value to be returned when retrieving a key that doesn’t exist in the Context.
Keys are created by calling the appropriate methods on the Context companion object:
// Keys are propagated in-process only
val UserID = Context.key[String]("userID", "undefined")
val SessionID = Context.key[Option[Int]]("sessionID", None)
val RequestID = Context.key("requestID", None)
There are three keys defined in the example above.:
-
UserIDas a key, with typeStringand a default value of"undefined". -
SessionIDas a key, with typeOption[Int]and a default value ofNone. -
RequestIDuses a shorter syntax for the very common case of having a broadcast key with typeOption[String].
It is recommended (although not necessary) to create Context keys as static members and reuse the key instance wherever it is needed.
Manipulating a Context #
As mentioned above, Context instances are immutable. Adding a key-value pair to a Context is achieved by actually creating
a new Context that includes or overrides a given key. Values can be retrived by calling .get(key) on any Context instance:
// Creating a Context with two keys
val context = Context.of(UserID, "1234", SessionID, Some(42))
// Reading values from a Context
val userID = context.get(UserID)
val sessionID = context.get(SessionID)
// The default value is returned for non-existent keys
val requestID = context.get(RequestID)
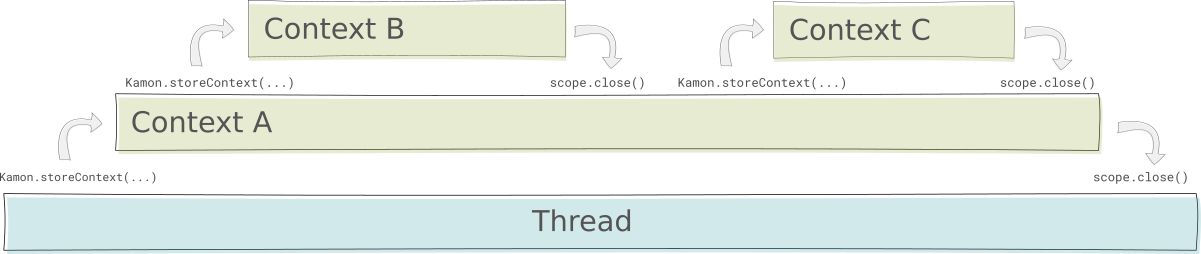
Current Context and Scopes #
The current Context always refers to the Context associated with the request currently being executed and it can be
accessed using the Kamon.currentContext() method. Once a Context is created for a given request it will be set as the
current Context for a finite period of time, controlled by a Scope. When a Scope is closed the previously current
Context is restored, which by default is Context.Empty.
The context storage works similar to Stack; every time you store a Context it becomes current, doing it several times
will make the most recently stored context be the current (like the top of a stack) but as the associated scopes get
closed, the previous contexts will become current again until eventually the current Context is Context.Empty again.
Effectively, the current Context is stored in a ThreadLocal but depending on the threading model of the frameworks and
libraries used to build your service a Context might need to be made current on several threads and for brief periods
of time. It is very important to close all created scopes timely, otherwise you risk leaving “dirty threads” that
might cause subsequent requests to see a previous and completely unrelated Context as the current Context.
A Context instance can become the current context by using any of the following methods:
-
Kamon.storeContext(context)which returns aScopeinstance that must be manually closed. -
Kamon.runWithContext(context) { ... }which takes a Context instance and makes it current while the code block executes. -
Kamon.runWithContextEntry(key, value) { ... }creates a new Context by adding the provided key to the current Context and makes it current while the code block executes. -
Kamon.runWithSpan(span) { ... }is similar to the above but explicitly works with the Span context Key.
// From this moment on there is a current context
val scope = Kamon.storeContext(context)
// Closing the Scope activates the previously stored context
scope.close()
Kamon.runWithContext(context) {
// Our context instance is the current Context
Kamon.runWithContextEntry(UserID, "5678") {
// The current context has a overridden UserID key
// The entry is propagated across process boundaries
}
}
It is recommended to use the Kamon.runWithXxx() variants as they will ensure that Scopes will be closed appropriately.
Codecs #
Codecs are used to encode and decode broadcast Context keys when crossing the process boundaries. There are two supported mediums for the codecs:
- HTTP Headers: Each entry codec is able to write any number of HTTP headers to encode its state and read any number of HTTP headers to decode it. This medium is used in all HTTP frameworks instrumentation like Akka HTTP, Play Framework, Http4s, etc.
-
Binary: Each entry codec must be able to encode and decode a value from and to a
ByteBuffer. This medium is used when a binary representation is more appropriate, like when sending messages to remote actor systems via Akka remoting or storing the Context in a message broker.
The codecs are configurable under the kamon.context.codecs section. Here is an extract from the default configuration
which sets the codecs for propagating the tracer’s Span:
kamon.context.codecs {
# Codecs to be used when propagating a Context through a HTTP Headers transport.
http-headers-keys {
span = "kamon.trace.SpanCodec$B3"
}
# Codecs to be used when propagating a Context through a Binary transport.
binary-keys {
span = "kamon.trace.SpanCodec$Colfer"
}
}
Broadcast String Codecs #
Since broadcast strings are so simple (just String values) Kamon can automatically provide codecs for them in the case
of binary mediums, but one additional piece of configuration is required for HTTP Headers: defining the header name to
be used:
kamon.context.codecs {
# If the application must read any of these keys it is necessary to create a
# broadcast string key with a matching name and read the value from the context:
#
# val requestIDKey = Key.broadcastString("request-id") // Do this only once, keep a reference.
# val requestID = Kamon.currentContext().get(requestIDKey)
#
string-keys {
request-id = "X-Request-ID"
}
}
Custom Codecs #
When in need to create a custom codec the Codecs.ForEntry[T] trait must be implemented and the fully qualified class
name for the implementation must be provided via configuration. The trait looks like the following:
object Codecs {
trait ForEntry[T] {
def encode(context: Context): T
def decode(carrier: T, context: Context): Context
}
}
A few important details to know when creating custom codecs:
- The implementation class must have a no-parameters constructor.
- A codec is responsible of encoding/decoding only one Context entry.
- There are only two allowed types for
T:TextMapandByteBuffer. - The
encodefunction might return an emptyTextMaporByteBufferif the provided Context doesn’t contain the key that a codec is responsible for. - The
decodefunction is expected to use the provided Context instance as a base for its return value. Typically a codec will try to read a value from the medium and either return the result ofcontext.withEntry(key, readValue)with the decoded value or simply return the provided Context if no value could be read.