Dear community,
Kamon 2.0 is out and ready to roll! For this release we focused primarily on simplifying the installation process and making sure that the core APIs are more solid and user friendly, since they will be the foundations upon which we will instrument the whole JVM world in the months to come!
Before we get into more details, let’s send a message to all the people who stopped by our Gitter channel and gave feedback, to the ones who raised issues, to the ones who helped testing out our release candidates and even super early experimental builds, to the ones who contributed new features and fixes, we say Thank You!, your help has been really important in shipping this release and we hope that you to stay around and continue growing with us.
Now, let’s see what is new in this release:
Dead Simple Initial Setup
Starting with this release, the entire instrumentation setup can be boiled down to just three steps: add the Kamon bundle
dependency, call Kamon.init() as the very first thing in your main method and finally, configure a reporter. That’s
it! No more chasing 10+ dependencies around and trying to figure out why some parts of the code are not instrumented, or
figuring out how to set up the instrumentation agent in different conditions. This initial setup brings everything that
Kamon can do with as little effort as possible.
These steps might be slightly different depending on whether you are using Play Framework or not, the easiest way to figure out what you need is to check out our new Get Started guide.
Kanela and the Bundle
Part of what enabled us to simplify the initial setup was a combination of Kanela and the Bundle. Kanela is a new instrumentation agent that replaces AspectJ and is the result of a long journey of experimentation and applying everything we learned over the years to produce a new instrumentation mechanism that plays nicely with Kamon. Since this release, AspectJ is not supported anymore and all instrumentation has been rewritten to work with Kanela.
The other half of simplifying the setup comes from the Bundle, which is just a new distribution of Kamon that includes
all the instrumentation modules and the Kanela agent, including the ability to attach Kanela to the currently running
JVM. When you call Kamon.init(), Kamon tries to find the Bundle and make it attach to the JVM in order to apply all
the instrumentation that comes with it. That’s why it is so important for it to be the first thing you do when starting
your app.
We are still publishing all the instrumentation as separate libraries in case that you want to keep adding specific versions as in all previous Kamon releases, but we highly recommend that you simply switch to the bundle and keep track of just one dependency.
The Kamon Status Page
Have you ever installed Kamon in a service, but you had no way of knowing whether the instrumentation was actually working or if metrics were being tracked at all? You are not alone, and the new Kamon Status Page is here to help with that.
When an application instrumented with Kamon is started, you can head over to localhost:5266 and have a quick look at basic information that can tell you whether the setup went fine. It looks a bit like this:
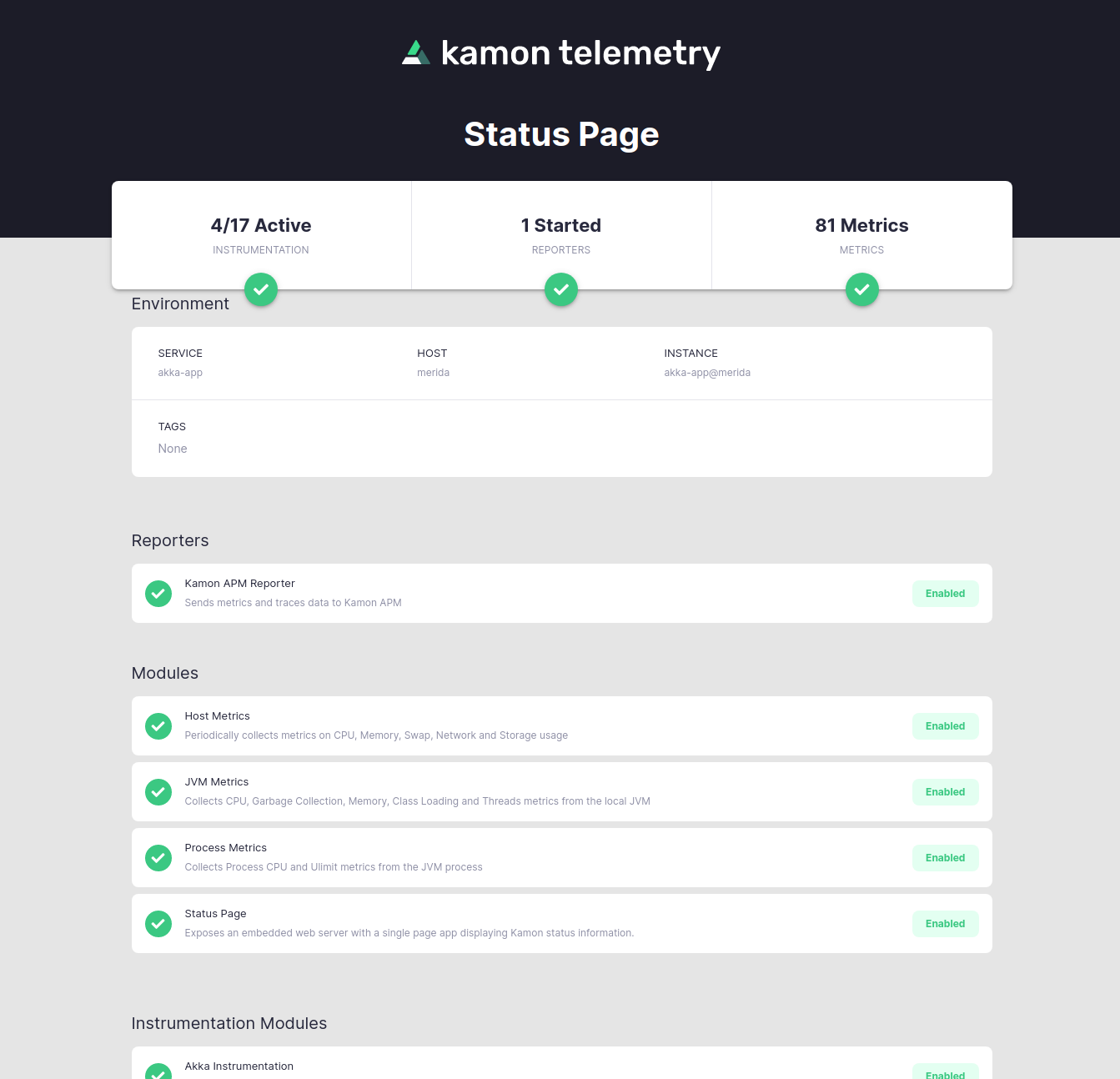
With the Kamon Status Page you can know whether instrumentation is working, what modules and reporters are running, what metrics are being tracked and what instrumentation modules are in use. We don’t know how we survived so long without a tool like this, and we are just getting started with it.
More features should be coming soon!
API Changes
We put a lot of effort on cleaning up the core APIs for context propagation, metrics and tracing, with a special emphasis on making sure that the user-facing APIs are documented, easy to understand and usable from any JVM language. As a result of these efforts, we introduced several breaking changes. The impact of those changes will vary depending on whether you were just using automatic instrumentation or you were actively using the Kamon APIs to manually instrument applications. Please head over to the Migration Guide for more information on how to upgrade.
What’s Next?
This release is a huge deal to us, for several reasons ranging from the fact that we love making our users’ lives easier with a super simple initial setup all the way up to finally getting rid of annoyances and less than ideal APIs for some of the core features in Kamon. This feels like we just unlocked a bunch of “achievements” in the instrumentation tools game!
It doesn’t stop here, though. This release gives us a solid foundation so that we can use focus a lot more on integrations, both on the reporters and instrumentation sides! Just as we are writing this announcement, there are members of the community working on instrumenting Kafka producers, consumers and streams, others working on the Cassandra drivers and this is the exact kind of work that we hope to be doing in the following months: more instrumentation, more reporters, more features built on top of the same foundations of this release.
Now, head over to the Get Started Guide and start instrumenting your services, enjoy!