Dear people from the community, we are extremely pleased to announce that after months of efforts, Kamon 1.0 is
finally out!. If you are already running Kamon 0.6.x or you are part of the adventurers who are already using
1.0.0-RCs in production, then it’s time to upgrade!
Before we get into it: Thanks. Thank you people. Thanks a lot! We got here thanks to a bunch of people giving us feedback, telling us about their problems and even issuing pull requests with solutions. Without all that help (and coffee, lots of coffee) we couldn’t have reached this point, we (Diego and Ivan) want to send our most sincere Thank you, you rock :).
Into the New Beast
There are several exciting changes in this release and probably we can summarize them around three fundamental pillars:
- A improved dimensional metrics model.
- A completely rewritten tracer with native support for distributed tracing.
- A new context management and propagation API.
We wrote a migration guide that talks in more detail about what changed since 0.6.x, but a quick high level
overview here won’t hurt anyone:
The changes to our metrics API are probably the simplest and most obvious ones, now all metrics have only two base
properties: a name and a set of tags. This aligns with pretty much every modern time series database and service out
there and makes it simpler to create reporting modules since the required logical overhead of mapping our old Entity
with instruments into name + tags is gone. Metrics and tagged dimensions FTW!
Our new tracer, well, this is a complete new thing; it doesn’t share a single line of code with what we had in Kamon
0.6.x. and this is definitely for the better. Our new tracing infrastructure revolves around Spans that model computations
and interactions between services. These Spans have a hierarchical relationship between each other (à la Dapper) and
can tell you the entire store of how a single request navigated through your whole microservices jungle.
Let’s summarize that in a more effective way. Just take a look at this screenshot from our Monitoring Akka Quickstart recipe:
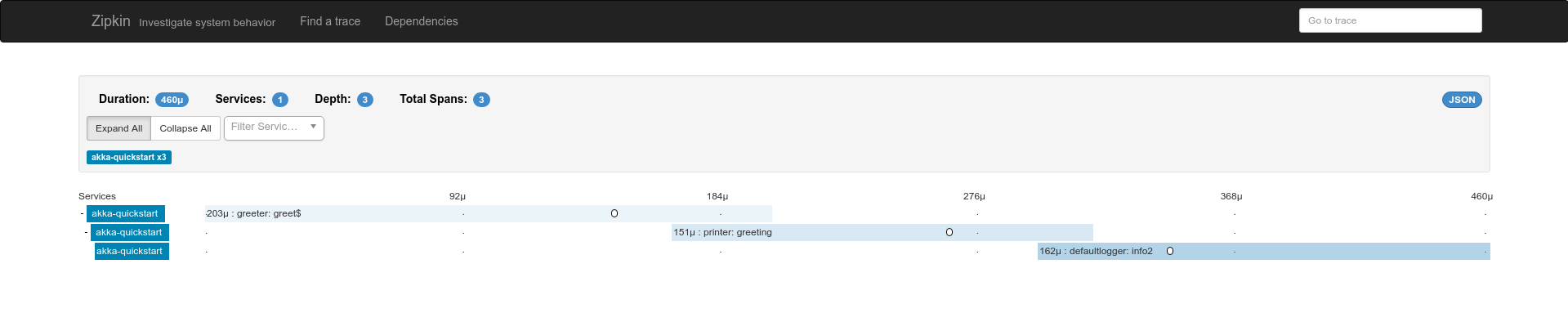
Now imagine getting that across JVMs, with microservices talking to each other through HTTP or Akka Remote/Cluster. All of that detail in a single trace that tells you exactly what happened for a given request.
One thing that didn’t change was the fact that both metrics and traces can be gathered without modifying your application code, it just got better by giving you more visibility with the very same integration effort!
Finally, the context management and propagation API came to replace what we previously called a TraceContext. This was
a unexpected turn in the process and maybe a bit of context (pun intended) on why this API came to life will help you
understand better why it exists: we were working on getting a simple and cleanly scoped API for the new tracer that
would satisfy the obvious tracing needs and, additionally, make sure that users can propagate custom bits of information
across asynchronous and JVM boundaries. There was a conflict here, though: in order to allow custom data to be propagated
we would need to have APIs on our Spans that would allow us to put and retrieve this data and working against our goal
of having a cleanly scoped API, but then it hit us… what people really want to do is to propagate Context across
boundaries, the fact that most of the time the Context has a Span doesn’t mean that the Span is the Context, since a
very common use case is to propagate external correlation IDs and user data as well, so, the whole Context API was born
and our tracer and instrumentation use it to create and retrieve Spans. A funny fact is, this is not a new or
revolutionary approach, Finagle and gRPC already have similar mechanisms, we just created a implementation of
this that perfectly suits Kamon.
Available Modules
We started migrating modules to Kamon 1.0 based on the usage data we have, community demand and time availability, but
not all have been upgraded just yet. You can drop us a line on the Gitter channel or open an issue on Github
if you need something that has not been upgraded yet.
Now, the lucky modules currently available are:
- Core includes all metrics, tracing and context management APIs.
- Akka for actor metrics and tracing inside a single JVM.
- Akka Remote has now serialization and remoting metrics and is able to trace messages across remote actor systems.
- Akka HTTP with client and service side tracing and HTTP server metrics.
- Futures bring automatic context propagation for Scala, Finagle and Scalaz futures.
- Executors collects executor service metrics.
- Play Framework with client and server side tracing.
- JDBC gives you metrics and tracing for JDBC statements execution and Hikari pool metrics.
- Logback comes with utilities for adding trace IDs to your logs and instrumentation to keep context when using async appenders.
- System Metrics gathers host, process and JVM metrics.
Aside from those being upgraded or spin off from other modules, we got some completely new reporting modules as well:
- Prometheus exposes a scrape endpoint with all available metrics.
- Zipkin for reporting trace data.
- Jaeger reports tracing data as well.
- Kamon APM reports metrics and tracing data to Kamon APM
Versions, Versions and Versions
Starting from this release, we will no longer have the crazy big bang releases where everything was released with the
same version number, even if no changes were made to a given module. The only constraint we will have for now is to make
sure that module releases that are compatible with Kamon 1.x will have a 1.x version number. The next time you see a big
bang release is going to be when Kamon 2.0 comes out. It can totally happen that kamon-akka-http will have a 1.1
release in the following weeks and use kamon-core version 1.0 since releases will be compatible.
Stay tuned on this blog and on @kamonteam for the latest news and releases.
This is it for now. There is still a lot of pending work, documentation to be written and/or updated, optimizations that could be applied and many new feature requests based on all the feedback we received over time. Keep sending your good wishes and feedback as it remains to be the main fuel powering our efforts.
Enjoy!
PS: As a small personal note, here is a (sort of old) tweet that deserves to be brought back, given the importance of this release in our greater goal: make Kamon the monitoring tool for applications running on the JVM.
Here is the very last slide from my talk, which I couldn't show but remains absolutely true: pic.twitter.com/N64zYdzsP3
— Ivan Topolnjak (@ivantopo) June 10, 2015</blockquote>
We didn’t go crazy yet :)